Bài 7: Machine Learning - Supervised Learning
Học có giám sát là một trong những mô hình học tập quan trọng liên quan đến việc traing cho máy.Ta sẽ cùng tìm hiểu chi tiết trong bài này.
1. Thuật toán học có giám sát :
Có một số thuật toán có sẵn để học có giám sát. Một số thuật toán được sử dụng rộng rãi của học có giám sát như sau:
- k-Nearest Neighbours
- Decision Trees
- Naive Bayes
- Logistic Regression
- Support Vector Machines
2. k-Nearest Neighbours :
k-Nearest Neighbours - gọi đơn giản là mô hình kNN , một kỹ thuật thống kê có thể được sử dụng để giải các bài toán phân loại và hồi quy. Ta hãy thảo luận về trường hợp phân loại một đối tượng không xác định bằng kNN. Xem xét sự phân bố của các đối tượng như trong hình dưới đây
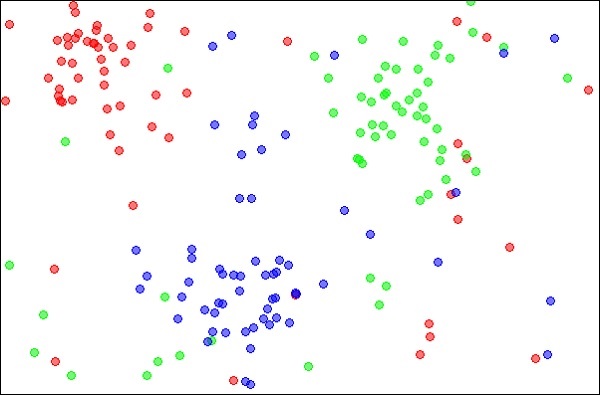
Sơ đồ cho thấy ba loại đối tượng, được đánh dấu bằng các màu đỏ, xanh lam và xanh lục. Khi bạn chạy trình phân loại kNN trên tập dữ liệu trên, ranh giới cho từng loại đối tượng sẽ được đánh dấu như hình dưới đây:
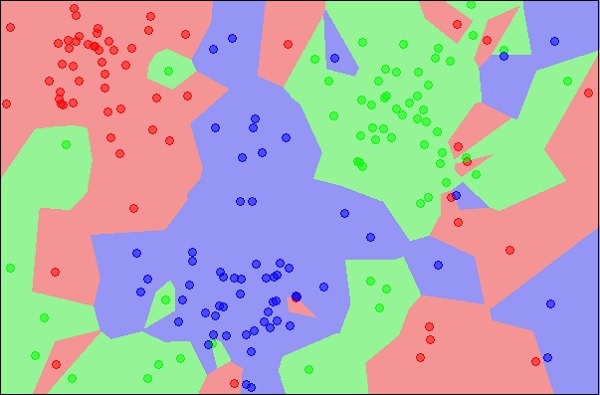
Bây giờ, hãy xem xét một đối tượng mới chưa biết mà bạn muốn phân loại là đỏ, lục hoặc lam. Điều này được mô tả trong hình bên dưới.
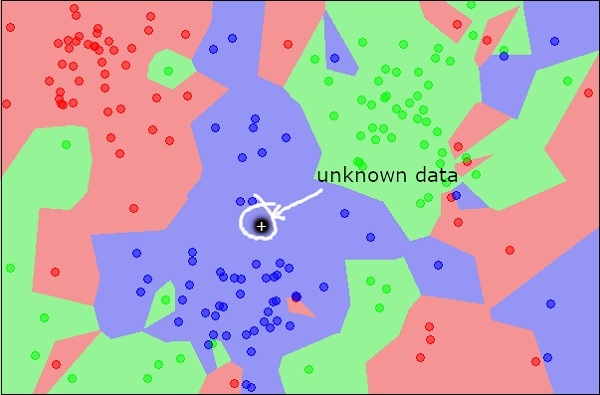
Như trên hình, điểm dữ liệu không xác định thuộc về một lớp các đối tượng màu xanh lam. Về mặt toán học, điều này có thể được kết luận bằng cách đo khoảng cách của điểm chưa biết này với mọi điểm khác trong tập dữ liệu. Khi làm như vậy, bạn sẽ biết rằng hầu hết các lân cận của nó có màu xanh lam. Khoảng cách trung bình đến các đối tượng màu đỏ và xanh lá cây chắc chắn sẽ nhiều hơn khoảng cách trung bình đến các đối tượng màu xanh lam. Do đó, vật thể không xác định này có thể được phân loại là thuộc lớp màu xanh lam.
Thuật toán kNN cũng có thể được sử dụng cho các bài toán hồi quy. Thuật toán kNN có sẵn để sử dụng trong hầu hết các thư viện ML.
3. Decision Trees :
Dưới đây là một cây quyết định đơn giản ở định dạng lưu đồ:
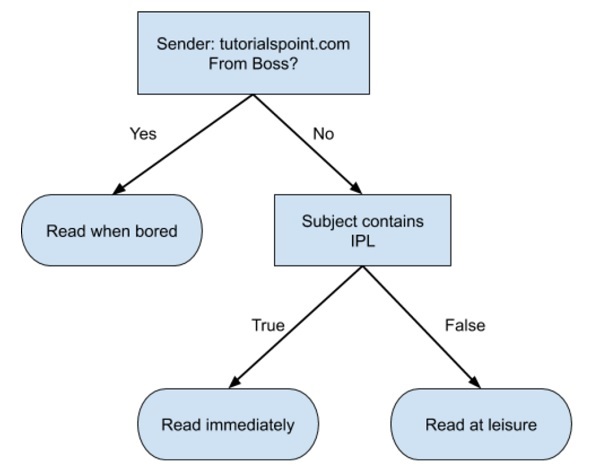
Bạn sẽ tiến hành viết code dể phận loại dữ liệu input dựa vào lưu đồ ở trên. Trong trường hợp trên, ta đang cố gắng phân loại một email đến để quyết định thời điểm đọc nó.
Trên thực tế, các cây quyết định có thể lớn và phức tạp. Có một số thuật toán có sẵn để tạo và duyệt những cây này. Là một người đam mê Machine Learning, bạn cần hiểu và nắm vững các kỹ thuật tạo và duyệt decision trees.
4. Naive Bayes
Naive Bayes được sử dụng để tạo bộ phân loại. Giả sử bạn muốn phân loại các loại trái cây từ một giỏ trái cây. Bạn có thể sử dụng các đặc điểm như màu sắc, kích thước và hình dạng của trái cây, Ví dụ: bất kỳ trái cây nào có màu đỏ, hình tròn và đường kính khoảng 10 cm đều có thể được coi là Apple. Vì vậy, để đào tạo mô hình, bạn sẽ sử dụng các tính năng này và kiểm tra xác suất để một tính năng nhất định phù hợp với các ràng buộc mong muốn. Xác suất của các tính năng khác nhau sau đó được kết hợp để đi đến xác suất một loại trái cây nhất định là Apple. Naive Bayes thường yêu cầu một số lượng nhỏ dữ liệu huấn luyện để phân loại.
5. Logistic Regression
Hình dưới đây sẽ chỉ rõ sự phân bố điểm dữ liệu XY :
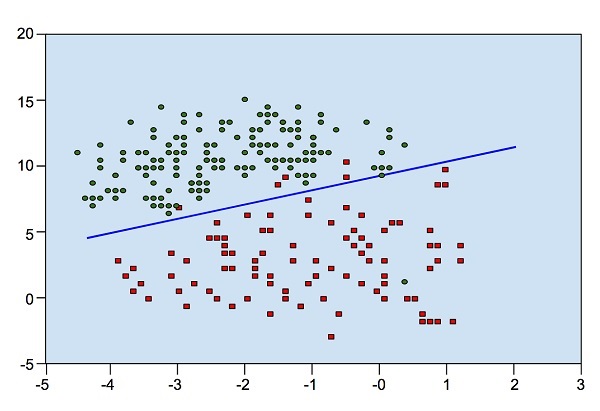
Từ sơ đồ, chúng ta có thể kiểm tra trực quan sự tách biệt của các chấm đỏ khỏi các chấm xanh. Bạn có thể vẽ một đường ranh giới để tách các chấm này ra. Bây giờ, để phân loại một điểm dữ liệu mới, bạn sẽ chỉ cần xác định điểm đó nằm ở phía nào của đường thẳng.
6. Support Vector Machines
Nhìn vào sự phân bố dữ liệu sau đây. Ở đây ba lớp dữ liệu không thể được phân tách một cách tuyến tính. Các đường cong biên là phi tuyến tính. Trong trường hợp như vậy, việc tìm phương trình của đường cong trở thành một công việc phức tạp.
Support Vector Machines (SVM) rất hữu ích trong việc xác định ranh giới ngăn cách trong những tình huống như vậy.

