Bài 6: Machine Learning - Phân loại (p2)
2. Unsupervised Learning :
Trong học không giám sát (unsupervised learning), ta không chỉ định một biến đích cho máy, thay vào đó ta sẽ hỏi máy "Bạn có thể cho tôi biết điều gì về X?". Cụ thể , ta đưa ta một tập dữ liệu X, ta có thể hỏi những câu hỏi như " 5 nhóm tốt nhất mà ta có thể tạo ra từ X là gì" hoặc "Những tính năng nào đặc biệt nhất trong X". Để có thể trả lời cho những câu hỏi như vậy, số lượng điểm dữ liệu mà máy yêu cầu để suy ra một thuật toán sẽ rất lớn. Trong trường họp học có giám sát, máy có thể được huấn luyện thậm chí khoảng vài nghìn điểm dữ liệu. Tuy nhiên trong trường học học không giám sát, số điểm dữ liệu được chấp nhận hợp lý cho việc học tập bắt đầu từ vài triệu điểm dữ liệu. Ngày nay, dữ liệu thường có sẵn rất nhiều. Dữ liệu lý tưởng là dữ liệu đã được xử lý. Tuy nhiên, lượng dữ liệu liên tục được tạo ra trong mạng xã hội, hầu hết trong các trường hợp, việc quản lý dữ liệu là bất khả thi
Hình ở dưới đây cho thấy ranh giới gữa các chấm màu vàng và đỏ được xác định bởi học không giám sát. Bạn có thể thấy rõ ràng máy sẽ có thể xác định lớp của từng chấm đen với độ chính xác khá tốt.
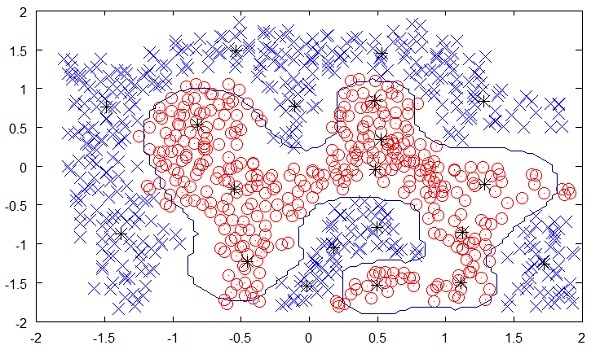
Việc học không giám sát đã cho thấy một thành công lớn trong nhiều ứng dụng AI hiện đại, chẳng hạn như nhận diện khuôn mặt, phát hiện đối tượng, v.v.
3. Reinforcement Learning :
Tôi có một chú chó cưng tên là Lu .Ta sẽ xem xét việc huấn luyện Lu như thế nào. Tôi ném quả bóng đến một khoảng cách nhất định và yêu cầu Lu lấy nó mang trở lại cho tôi. Mỗi khi Lu làm đúng, tôi thưởng cho nó một đồ ăn. Dần dần nó sẽ biết rằng công việc nó đang làm là đúng. Khái niệm này được áp dụng trong học tăng cường. Kỹ thuật này ban đầu được phát triển cho các máy chơi game. Máy được đưa ra một thuật toán để phân tích tất cả các nước đi có thể xảy ra ở mỗi giai đoạn của trò chơi. Máy có thể chọn ngẫy nhiên một trong các bước di chuyển. Nếu nước đi đúng, máy được thưởng, nếu không sẽ bị phát. Từ từ, máy sẽ bắt đầu phân biệt được các bước đi đúng và sai, sau nhiền lần lặp lại sẽ học cách giải câu đố trò chơi với độ chính xác cao hơn. Độ chính xác của việc giành chiến thắng trong trò chơi sẽ cải thiện khi máy chơi ngày càng nhiều trò chơi.
Toàn bộ quá trình có thể được mô tả như sau :
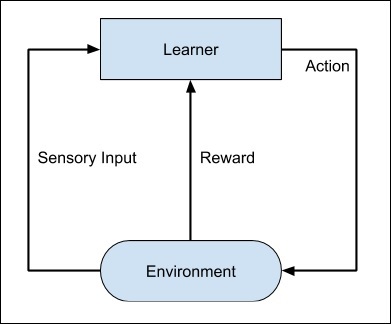
Kỹ thuật học máy này khác so với học có giám sát ở chỗ là bạn không cần cung cấp các cặp input/output được gắn nhãn. trọng tâm là tìm sự cân bằng giữa việc khám phá các giải pháp mới với việc khai thác các giải pháp đã học
4. Deep Learning
Học sâu là một mô hình dựa trên Mạng thần kinh nhân tạo (ANN), cụ thể hơn là Mạng thần kinh hợp pháp (CNN). Có một số kiến trúc được sử dụng trong học sâu như deep neural networks, deep belief networks, recurrent neural networks (RNN),convolutional neural networks(CNN).
Các mạng này đã được ứng dụng thành công trong việc giải quyết các vấn đề về thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, tin sinh học, thiết kế thuốc, phân tích hình ảnh y tế và trò chơi. Có một số lĩnh vực khác mà học sâu được chủ động áp dụng. Học sâu đòi hỏi sức mạnh xử lý khổng lồ và dữ liệu khổng lồ, ngày nay thường dễ có sẵn.
Ta sẽ nói chi tiết hơn về học sâu trong các chương tới.
5. Deep Reinforcement Learning
Học tăng cường sâu (DRL) kết hợp các kỹ thuật của cả học sâu và tăng cường. Các thuật toán học tăng cường như Q-learning hiện được kết hợp với học sâu để tạo ra một mô hình DRL mạnh mẽ. Kỹ thuật này đã đạt được thành công lớn trong các lĩnh vực robot, trò chơi điện tử, tài chính và chăm sóc sức khỏe. Nhiều vấn đề nan giải trước đây đã được giải quyết bằng cách tạo các mô hình DRL. Có rất nhiều nghiên cứu đang diễn ra trong lĩnh vực này và điều này đang được các ngành theo đuổi rất tích cực.
Mình đã giới thiệu ngắn gọn về các mô hình học máy khác nhau, bây giờ chúng ta hãy khám phá sâu hơn một chút về các thuật toán khác nhau có sẵn trong các mô hình này

