Bài 16: Mạng neuron tích chập
Từ năm 1996, siêu máy tính Deep Blue của IBM đã đánh bại con người trong trò chơi cờ vua những tới tận những năm gần đây, máy tính mới có thể đạt tới ngưỡng của con người trong việc nhận dạng những thứ rất đơn giản như ảnh một chú cún hay lời nói bên trong âm thanh. Tại sao điều này rất dễ dàng với con người nhưng lại là thách thức với máy tính?
Câu trả lời là nhận thức của chúng ta xảy ra bên ngoài ý thức, nó diễn ra một cách tự nhiên trong các mô-đun thị giác, thính giác và các giác quan khác trong não của chúng ta. Lúc mà ý thức của chúng ta quyết định đâu là cái gì, tín hiệu đã được chuyển hoá hết thành thông tin có ý nghĩa rồi. Lấy ví dụ khi bạn nhìn vào một chú cún, bạn không thể quyết định loại bỏ chú cún đó ra trong những hình ảnh bạn nhìn thấy.
Mạng neuron tích chập (Convolutional Neural networks - CNN) xuất hiện trong những nghiên cứu về vỏ não thị giác từ năm 1980. Những năm gần đây, năng lực tính toán của máy tính được nâng cao, dữ liệu trong thời đại số bùng nổ cộng với những nghiên cứu mới trong việc huấn luyện mạng neuron hiệu quả đã đưa CNN đạt được hiệu suất như con người trong nhiều lĩnh vực cần xử lý hình ảnh trực quan như tìm kiếm ảnh, xe tự lái, hệ thống phân loại ảnh video,... Trong bài này mình sẽ cùng các bạn tìm hiểu những thành phần làm lên sự thành công của mạng neuron tích chập này.
Nghiên cứu về vỏ não thị giác cho thấy, một số neuron thần kinh chỉ phản ứng với một vùng nhỏ của bức ảnh, trong khi một số neuron khác lại phản ứng với vùng ảnh to hơn, những vùng to này là kết hợp của các vùng ảnh nhỏ phía trước. Ngoài ra một số neuron phản ứng với những đường kẻ nằm ngang, số khác lại phản ứng với những đường nằm dọc (Hình 1).
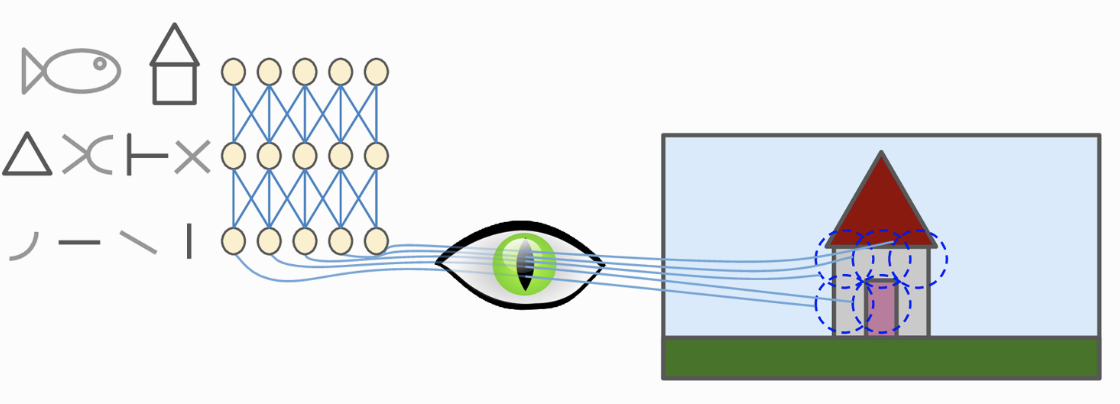
Những quan sát này dẫn tới một ý tưởng là những neuron tầng cao tổng hợp những đặc trưng từ tầng thấp, nhưng mỗi neuron chỉ nhìn vào một phần của tầng tầng bên dưới nó chứ không tổng hợp toàn bộ thông tin từ tầng dưới. Nghiên cứu về vỏ não thị giác đã truyền cảm hứng để năm 1998, Yann Lecun đã giới thiệu kiến trúc CNN LeNet với thành phần cốt lõi là hai khối Convolutional và Pooling. Hãy cùng tìm hiểu hai khối này bao gồm những gì.
Convolutional layer
Tầng Convolutional là khối quan trọng nhất trong một mạng CNN. Các neuron ở tầng đầu tiên không kết nối trực tiếp tới toàn bộ các pixel của ảnh đầu vào mà chỉ những pixel trong một vùng nhỏ. Tương tự như thế, các neuron ở tầng cao không kết nối trực tiếp tới toàn bộ tầng thấp mà chỉ kết nối tới một phần các neuron tầng dưới nó. Kiến trúc này sẽ cho phép các tầng thấp tập trung để trích xuất thông tin cấp thấp, còn tầng cao tổng hợp những thông tin trừu tượng hơn (Hình 2). Cách xử lý như này cũng giống với con người, điều đó giải thích lý do tại sao mạng CNN rất phù hợp cho xử lý ảnh.

Kernel
Chi tiết hơn. Mỗi neuron tại vị trí hàng i cột j sẽ kết nối với các neuron tầng dưới thuộc hàng từ i tới i + fh - 1, cột từ j tới j + fw -1. với fh và fw là chiều cao và chiều rộng của kernel (góc nhìn của một neuron). Để layer tầng cao có số neuron giống với tầng dưới nhằm tiện cho việc tính toán, trong thực tế ta sẽ thêm một số hàng và cột có giá trị 0 xung quanh tầng dưới (Zero padding). (Hình 3)

Stride (Bước nhảy)
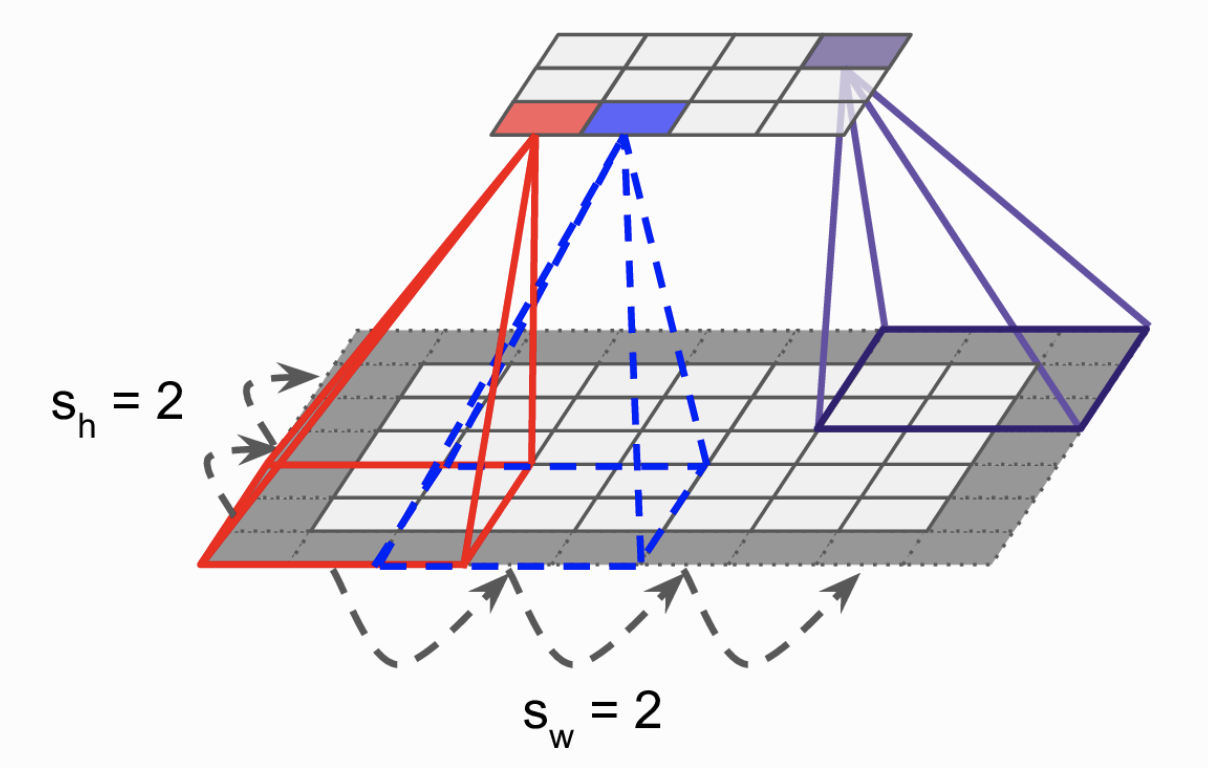
Có thể thực hiện việc trích chọn đặc trưng tầng thấp thành thành đặc trưng tầng cao có kích thước nhỏ hơn bằng việc nhảy cóc việc quét các kernel qua ảnh. Hình 3 bước nhảy của các kernel là 1. Hình 4 biểu thị bước nhảy 2. Các bạn có thể thấy số lượng neuron ở tầng trên thấp hơn đáng kể ở tầng dưới. Khi đó mỗi neuron tại vị trí hàng i cột j sẽ kết nối với các neuron tầng dưới thuộc hàng từ i * sh tới i * sh + fh - 1, cột từ j * sw tới j * sw + fw -1. với fh và fw. Với sh là bước nhảy theo chiều dọc và sw là bước nhảy theo chiều ngang
Feature map
Kernel được tính toán trên ảnh đầu vào, duyệt qua toàn bộ ảnh và cho ra một ma trận mới (bằng hoặc nhỏ hơn ma trận ảnh đầu vào tuỳ thuộc vào bước nhảy và kích thước kernel). Ma trận đầu ra này còn được gọi là Feature map. Với một ảnh đầu vào ta có thể sử dụng nhiều kernel, mỗi kernel sẽ cho ra một Feature map khác nhau. Hình 5.

Bạn có thể tưởng tượng ảnh đầu vào là một tập 3 Feature map, mỗi feature map đại diện cho một kênh màu. Sau đó sử dụng n kernel để cho ra một tập n Feature map cho tầng đầu tiên, và cứ thế sẽ có feature map cho các tầng tiếp theo. Khái niệm kernel bây giờ không chỉ có 2 chiều cao và rộng nữa mà sẽ thêm chiều sâu, đó chính là số lượng feature map ở tầng dưới. Lấy ví dụ kernel ở tầng đầu tiên sẽ có kích thước là [sh, fw, 3] với 3 chính là số kênh màu của ảnh đầu vào.
Triên khai tính toán Convolutional trên tensorflow
Import một số thư viện cần thiết
from sklearn.datasets import load_sample_image
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as pltLoad ảnh và tính toán các tham số của ảnh
flower = load_sample_image("flower.jpg")
batch_size = 1
height, width, channels = flower.shapeTạo kernel
kernels = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
kernels[:, 3, :, 0] = 1 # vertical line
kernels[3, :, :, 1] = 1 # horizontal lineTính toán phép nhân chập sử dụng tensorflow
outputs = tf.nn.conv2d([flower], kernels, strides=1, padding="SAME")Hiển thị kết quả đầu ra sử dụng matplotlib
fig=plt.figure(figsize=(16, 48))
fig.add_subplot(1, 3, 1)
plt.imshow(flower, cmap="gray") # ảnh gốc
fig.add_subplot(1, 3, 2)
plt.imshow(outputs[0, :, :, 0], cmap="gray") # feature map ngang
fig.add_subplot(1, 3, 3)
plt.imshow(outputs[0, :, :, 1], cmap="gray") # feature map dọc
plt.show()
Ở đây các kernel chúng ta tự định nghĩa. Tuy nhiên trong thực tế, những kernel này sẽ được tự động học dựa trên dữ liệu huấn luyện. Phần tiếp theo chúng ta sẽ tìm hiểu thành phần quan trọng thứ hai trong một mạng neuron tích chập đó là thành phần Pooling

