Bài 18: Rút gọn : Phần 1
1. Giới thiệu về Machine Learning - AI - Machine Learning cơ bản
Lập trình thuật toán là một việc đương nhiên tới mức tầm thường từ thủa sơ khai khi máy tính được tạo ra. Chúng ta đã quen với việc tạo ra các ứng dụng hay hệ thống bằng cách chia nhỏ các yêu cầu thành các bài toán con và từ những bài toán con này các đoạn code được viết ra. Các bài toán đơn vị chính là những bài toán điều kiện (if else), vòng lặp (while, for) hay tính toán cộng trừ nhân chia mà chúng ta hay triển khai khi lập trình.Lấy ví dụ nếu chúng ta cần giải quyết bài toán tìm xu hướng của giá bitcoin, một trong số những hướng giải quyết có thể đưa ra tìm nguồn dữ liệu, tính toán chênh lệch giữa các ngày và kết luận xu hướng dựa trên các ngày gần đó. Một ví dụ khác nếu như bài toán đặt ra là lập trình trò chơi Balls Bricks Breaker. Dữ liệu ta có là vị trí của quả bóng, vị trí các viên gạch. Luật chơi là quả bóng được bắn lên, đập vỡ các viên gạch rồi quay ngược trở lại. Nếu quả bóng rơi xuống đáy người chơi có thể mất lượt.Có một điểm chung của các bài toán ví dụ trên là chúng ta luôn phải xác định dữ liệu của bài toán, định nghĩa các luật để giải quyết bài toán và từ các luật và dữ liệu này câu trả lời hay các quyết định được đưa ra. Sơ đồ của quá trình này như ở hình (Hình 1). Các luật được cụ thể hoá bằng ngôn ngữ lập trình, dữ liệu có thể tới từ nhiều nguồn và cụ thể hoá thành các biến số trong chương trình hoặc lưu trữ trong các cơ sở dữ liệu.

Machine learning sắp xếp lại thứ tự của các thành phần một chút (Hình 2). Khi này dữ liệu và câu trả lời cần được xác định trước, các luật sẽ được đưa ra sau đó. Quay lại ví dụ trên, nếu ta có chuỗi các giá trị theo thời gian của bitcoin và nhãn xu hướng cho từng khoảng chuỗi giá trị đó, Machine learning sẽ giúp chúng ta đưa ra luật để xác định một khoảng chuỗi giá trị là tăng hay giảm. Cách làm này đặc biệt hữu ích để giải quyết những bài toán mà luật để giải quyết không rõ ràng.Lấy ví dụ bài toán phát hiện loại chuyển động từ dữ liệu tốc độ. Nếu chỉ có các chuyển động chỉ là đi bộ, chạy hay đạp xe, chúng ta có thể định nghĩa một số luật để giải quyết. Nhưng nếu yêu cầu phân loại thêm loại chuyển động là đánh golf, đá bóng, hay chơi cầu lông chẳng hạn, số lượng luật đưa ra là quá nhiều và thực tế có thể không khả thi. Machine learning sẽ là vị cứu tinh trong những trường hợp như thế này. Việc thu thập dữ liệu và nhãn dữ liệu đơn giản hơn nhiều việc nghĩ ra thuật toán để giải quyết tất cả các trường hợp có thể xảy ra.Nhìn vào hai biểu đồ, thực thế thì Machine learning và lập trình theo luật cũng khá giống nhau. Chỉ khác ở thứ tự các input và output. Một bên từ dữ liệu và thuật toán ta suy ra câu trả lời. Một bên từ dữ liệu và câu trả lời, thuật toán được sinh ra. Học máy là một mô hình lập trình mạnh mẽ và thú vị. Nó mở ra những khả năng mới mà lập trình theo luật trước đây không thể thực hiện được. Machine learning là mô hình lập trình kiểu mới, còn được ví như là Sofware 2.0

Deep learning là một bài toán con của Machine learning. Neural network là một triển khai cụ thể của khái niệm Deep learning. Thực tế Neural network chỉ là một triển khai nâng cao hơn một chút so với Machine learning mà chúng ta vừa bàn. Điểm khác biệt cơ bản có thể được so sánh ở Hình 3. Đối với Machine learning, việc tìm ra đặc trưng của dữ liệu là phần của của con người, từ các đặc trưng của dữ liệu đó, các luật mới được đưa ra. Đối với Deep learning, các đặc trưng này được tự động được tìm ra trong quá trình tạo luật.
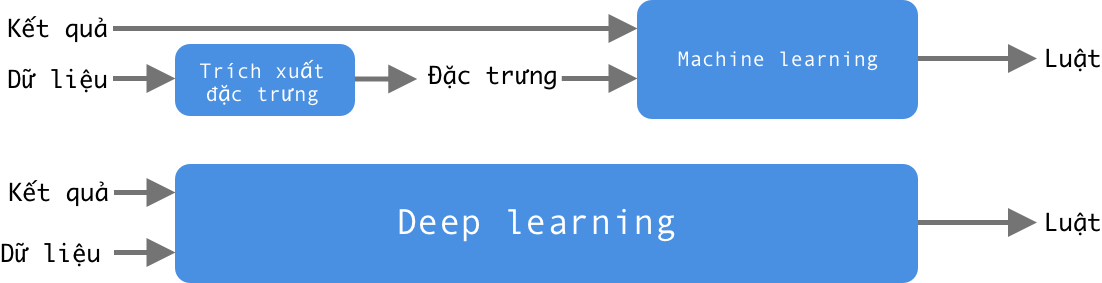
Việc trích chọn đặc trưng từ dữ liệu một cách thủ công tương đối khó và nhiều khi cần kiến thức chuyên sâu về miền lĩnh vực của dữ liệu đó. Lấy ví dụ bài toán phân biệt chó mèo. Nếu giải quyết bài toán với Machine learning, bước đầu tiên chúng ta phải làm là định nghĩa các đặc trưng và tìm các đặc trưng đó từ ảnh (có râu không, có tai không, có nhọn không,....). Rồi từ những đặc trưng đó sử dụng thuật toán phân loại của Machine learning để đưa ra luật nhận dạng. Còn đối với Deep learning, tất cả những thứ ta cần là ảnh đầu vào và nhãn của ảnh, không cần định nghĩa bất kỳ đặc trưng gì, các đặc trưng sẽ được tự động đưa ra. Hình 4.Trong điều kiện dữ liệu nhiều, việc sử dụng deep learning để trích suất tự động các đặc trưng tỏ ra hiệu quả hơn đáng kể. Đương nhiên lựa chọn giải thuật nào nào cũng có ưu và nhược điểm một bên cần nhiều dữ liệu (Deep learning), một bên cần trích chọn đặc trưng cẩn thận (Machine learning).

Bài 2: Machine Learning - AI ngày nay có thể làm gì? - AI - Machine Learning cơ bản
Khi bạn tag một khuôn mặt trong ảnh của Facebook, AI chạy thuật toán bên dưới và nhận diện các khuôn mặt có trong bức ảnh đó. Gắn thẻ khuôn mặt có mặt khắp mọi nơi, trong một số ứng dụng hiển thị ảnh có khuôn mặt con người . Tại sao chỉ nhận diện khuôn mặt con người ? Có một số ứng dụng phát hiện ra các đối tượng như chó, mèo, hoa, ô tô,...Ngoài ra còn được sử dụng ô tô tự lái chạy trên đường, có khả năng phát hiện và tránh các đối tượng trong thời gian thực điều khiển xe. Ngoài ra, khi bạn đi du lịch, bạn sử dụng Google Map để tìm hiểu các tình huống về thời gian trong thời gian thực và được khuyến khích đi con đường tốt nhất do Google đề xuất tại thời điểm đó. Đó đều là những ứng dụng đều được khai thác bởi kỹ thuật phát hiện đối tượng trong thời gian thực
Sau đây, ta hãy cùng xem xét các ví dụ về ứng dụng Google dịch mà ta thường xuyên sử dụng khi tra các từ phục vụ học tập hoặc là đến các quốc gia khác. Ứng dụng dịch trực tuyến của Google trên điện thoại giúp ta có thể dễ dàng giao tiếp với người dân địa phương nói ngôn ngữ xa lạ với ta.
Có một số ứng dụng của AI mà chúng ta sử dụng thực tế ngày nay. Trên thực tế, mỗi người trong chúng ta đều sử dụng AI trong nhiều phần của cuộc sống, ngay cả khi ta không hề hay biết. AI ngày nay có thể thực hiện được các công việc cực kỳ phức tạp với độ chính xác và tốc độ cao. Ta sẽ cùng nói về một vào nhiệm vụ phức tạp để hiểu những khả năng mà ứng dụng AI có thể làm được
Tất cả chúng ta đều sử dụng Google Map trong việc di chuyển trong thành phố hằng ngày. Ứng dụng Google Map gợi ý đường dẫn nhanh nhất để đến điểm cần dến tại thời điểm đó. Khi ta đi theo con đường này, ta nhận ra rằng Google đã gần như đúng 100% trong các đề xuất của mình và ta tiết kiệm được thời gian của mình trong việc di chuyển
Bạn có thể hình dung được sự phức tạp liên quan đến việc phát triển loại ứng dụng này vì có nhiều con đường dẫn đến điểm đến và ứng dụng phải phán đoán tình hình giao thông ở mọi con đường , cung cấp cho bạn ước tính thời gian di chuyển cho mỗi con đường như vậy. Bên cạnh đó, hãy xem xét thực tế là Google Map bao phủ toàn bộ địa cầu. Không nghi ngờ gì nữa, rất nhiều kỹ thuật AI và máy học đang được sử dụng dưới lớp vỏ của các ứng dụng như vậy
Xem xét nhu cầu liên tục về sự phát triển của các ứng dụng như vậy, giờ đây bạn sẽ hiểu tại sao lại có nhu cầu đột ngột về các chuyên gia CNTT có kỹ năng AI
Bài 3: Machine Learning - AI truyền thống - AI - Machine Learning cơ bản
Cuộc hành trình của AI bắt đầu vào những năm 1950 khi sức mạnh tính toán chỉ bằng một phần nhỏ so với ngày nay. AI bắt đầu với các dự đoán được thực hiện bởi máy theo kiểu một nhà thống kê thực hiện các dự đoán bằng máy tính của mình. DO đó, toàn bộ sự phát triển AI ban đầu chủ yếu dựa trên các kỹ thuật thống kê.Trong bài này, chúng ta sẽ thảo luận chi tiết những kỹ thuật thống kê này mang ý nghĩa gì ?
Kỹ thuật thống kê:
Sự phát triển của các ứng dụng AI ngày nay bắt đầu bằng việc sử dụng các kỹ thuật thống kê truyền thống từ lâu đời. Các bạn hẳn đã sử dụng phép nội suy đường thẳng để dự đoán một giá trị trong tương lai. Có một số kỹ thuật thống kê khác được áp dụng thành công trong việc phát triển gọi là các chương trình AI. Các chương trình AI ngày nay phức tạp hơn rất nhiều và sử dụng các kỹ thuật vượt xa các kỹ thuật thống kê được sử dụng bởi các chương trình AI ban đầu Một số ví dụ về kỹ thuật thống kê được sử dụng để phát triển ứng dụng AI được liệt kê như sau :
- Hồi quy (Regression)
- Phân loại (Classification)
- clustering
- Lý thuyết xác suất (probability theories)
- Cây quyết định (Decistion Trees)
Ở đây, mình chỉ liệt kê một số kỹ thuật chính chủ yếu được sử dụng để các bạn bắt đầu với AI mà không làm bạn bất ngờ về sự rộng lớn của AI. Nếu bạn đang phát triển các ứng dụng AI dựa trên dữ liệu bị hạn chế, bạn sẽ sử dụng các kỹ thuật nàyTuy nhiên, ngày nay dữ liệu trở nên khổng lồ. Để phân tích loại dữ liệu khổng lồ mà ta đang có, các kỹ thuật thống kê không giúp ích được gì nhiều vì chúng có một số hạn chế riêng. Do đó, các phương pháp tiên tiến hơn như học sâu (deep learning) được phát triển để giải quyết nhiều vấn đề phức tạp.Ở các bài sau, chúng ta sẽ hiểu hơn machine learning là gì và cách nó được sử dụng để phát triển các ứng dụng AI phức tạp như thế nào?
Bài 4: Machine Learning - Machine Learning là gì? - AI - Machine Learning cơ bản
Hãy cùng xem xét biểu đồ ở dưới, biểu đồ thể hiện hình dạng giá nhà so với kích thước của nó :
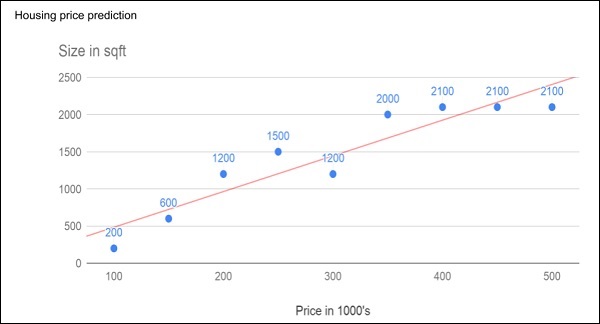
Sau khi vẽ các điểm dữ liệu trên biểu đồ mặt phẳng xy, ta sẽ tiến hành vẽ một đường phù hợp nhất để thực hiện dự đoán cho bất kì ngôi nhà nào có kích thước khác nhau.Ta sẽ cung cấp dữ liệu đã biết cho máy và yêu cầu máy tìm ra giá phù hợp nhất. Sau khi máy tìm được đường thẳng vừa vặn nhất, ta sẽ kiểm tra độ phù hợp của nó bằng cách cho ăn theo kích thước ngôi nhà đã biết, tức là giá trị Y trong đường thẳng trên. Sau đó, máy sẽ trả về giá trị X ước tính, tức là giá nhà dự kiến của ngôi nhà. Thuật toán có thể dễ dàng tìm được giá của một ngôi nhà có diện tích 3000 mét vuông hoặc thậm chí là lớn hơn. Đây được gọi là thuật toán hồi quy. Đặc biệt, thuật toán này được gọi là hồi quy tuyến tính vì mối quan hệ giữa các điểm dữ liệu X và Y là tuyến tínhTrong nhiều trường hợp, mối quan hệ giữa các điểm dữ liệu X và Y có thể không phải là một đường thẳng và nó có thể là một đường cong với một phương trình phức tạp. Nhiệm vụ của bạn bây giờ là tìm ra đường cong phù hợp nhất có thể để suy đoán các giá trị trong tương lai. Ta hãy xem hình ảnh sau :
Xem thêm ở đâyBạn sẽ sử dụng các kỹ thuật tối ưu hoá thuật toán để tìm ra phương trình cho đường cong phù hợp nhất. Và đây chính xác được gọi là máy học (machine learning)/ Bạn sử dụng các kỹ thuật tối ưu hoá đã biết để tìm ra giải pháp tốt nhất cho vấn đề của mình.Ở bài tiếp theo, chúng ta sẽ tìm hiểu sâu hơn về machine learning nhé .
Bài 5: Machine Learning - Phân loại - AI - Machine Learning cơ bản
Machine learning được phân loại chủ yếu như sau :
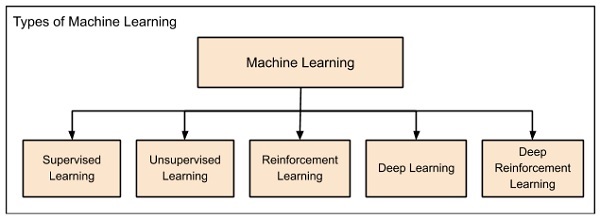
Machine learning phát triển từ trái sang phải như được hiển thị ở sơ đồ phía trên :
- Ban đầu, các nhà nghiên cứu bắt đầu với Học có giám sát( Supervised Learning). Đây là trường hợp dự đoán giá nhà ở đã thảo luận trước đó.
- Sau đó là học không giám sát( Unsupervised Learning ), ở đây máy móc có thể học bất cứ thứ gì mà không cần phải giám sát
- Các nhà khoa học phát hiện thêm rằng có thể là một ý tưởng hay khi máy tính thực hiện đúng công việc và được thưởng , và đó được gọi là Học tập tăng cường (Reinforcement Learning).
- Rất nhanh chóng, dữ liệu có sẵn ngày nay đã trở nên khổng lồ đến mức các kỹ thuật thông thường được phát triển cho đến nay không thể phân tích dữ liệu lớn và cung cấp cho chúng ta dự đoán.
- Do đó, Học sâu (Deep learning) đã xuất hiện trong đó bộ não con người được mô phỏng trong Mạng thần kinh nhân tạo (ANN) được tạo ra trong máy tính nhị phân của chúng ta.
- Máy hiện có thể tự học bằng cách sử dụng sức mạnh tính toán cao và tài nguyên bộ nhớ khổng lồ hiện có.
- Hiện tại, có thể thấy rằng Học sâu (Deep Learning) đã giải quyết được nhiều vấn đề nan giải trước đây
- Kỹ thuật này hiện đã được nâng cao hơn nữa bằng cách tặng thưởng cho các mạng Deep Learning khi thực hiện đúng công việc nào đó và cuối cùng là Deep Reinforcement Learning ra đời.
Bây giờ chúng ta hãy nghiên cứu chi tiết hơn từng loại này.
1. Supervised Learning :
Học tập có giám sát tương tự như việc huấn luyện một đứa trẻ tập đi. Bạn sẽ nắm tay trẻ, hướng dẫn trẻ cách đưa chân về phía trước, tự đi bộ để trình diễn, ... cho đến khi trẻ học cách tự đi.Học có giám sát bao gồm 2 bài toán : Hồi quy (Regression) và phân loại (Classificaiton)
a. Hồi quy (Regression) :
Tương tự, trong trường hợp học có giám sát, bạn đưa ra các ví dụ cụ thể đã biết cho máy tính. Bạn nói rằng đối với giá trị đặc trưng đã cho x1, đầu ra là y1, đối với x2 là y2, đối với x3 là y3, .... Dựa trên dữ liệu này, bạn cho phép máy tính tìm ra mối quan hệ thực nghiệm giữa x và y.Sau khi máy được huấn luyện theo cách này với đủ số điểm dữ liệu, bây giờ bạn sẽ yêu cầu máy dự đoán Y cho một X. Giả sử rằng bạn biết giá trị thực của Y cho X đã cho này, bạn sẽ có thể suy ra dự đoán của máy có đúng không.Do đó, bạn sẽ kiểm tra xem máy đã học hay chưa bằng cách sử dụng dữ liệu kiểm tra đã biết. Một khi bạn hài lòng rằng máy có thể thực hiện các dự đoán với mức độ chính xác mong muốn (giả sử từ 80 đến 90%), bạn có thể ngừng đào tạo thêm cho máy.Giờ đây, bạn có thể yên tâm sử dụng thuật toán để thực hiện các dự đoán trên các điểm dữ liệu chưa biết hoặc yêu cầu máy dự đoán Y cho một điểm X cho trước mà bạn không biết giá trị thực của Y. Bài tập này thuộc về hồi quy mà ta đã đề cập ở bài trước.
b. Phân loại (Classification):
Bạn cũng có thể sử dụng các kỹ thuật học máy cho các vấn đề phân loại. Trong các bài toán phân loại, bạn phân loại các đối tượng có bản chất tương tự thành một nhóm duy nhất. Ví dụ, trong một nhóm 100 sinh viên nói, bạn có thể muốn nhóm họ thành ba nhóm dựa trên chiều cao của họ : thấp, trung bình và cao. Đo chiều cao của từng học sinh, bạn sẽ xếp họ vào nhóm thích hợp.Bây giờ, khi một học sinh mới đến, bạn sẽ xếp anh ta vào một nhóm thích hợp bằng cách đo chiều cao của anh ta. Bằng cách tuân theo các nguyên tắc trong mô hình hồi quy, bạn sẽ đào tạo máy phân loại học sinh dựa trên đặc điểm của anh ta ( chiều cao ). Khi máy học cách các nhóm được thành lập, nó sẽ có thể phân loại chính xác bất kỳ học sinh mới nào chưa biết. Một lần nữa, bạn sẽ sử dụng dữ liệu thử nghiệm để xác minh rằng máy đã học được kỹ thuật phân loại của bạn trước khi đưa mô hình ứng dụng vào thực tế.Học giám sát là nơi AI thực sự bắt đầu hành trình của mình. Kỹ thuật này đã được áp dụng thành công trong một số trường hợp. mô hình này được sử dụng trong khi thực hiện nhận dạng chữ viết tay. Một số thuật toán đã được phát triển để học có giám sát
Bài 6: Machine Learning - Phân loại (p2) - AI - Machine Learning cơ bản
2. Unsupervised Learning :
Trong học không giám sát (unsupervised learning), ta không chỉ định một biến đích cho máy, thay vào đó ta sẽ hỏi máy "Bạn có thể cho tôi biết điều gì về X?". Cụ thể , ta đưa ta một tập dữ liệu X, ta có thể hỏi những câu hỏi như " 5 nhóm tốt nhất mà ta có thể tạo ra từ X là gì" hoặc "Những tính năng nào đặc biệt nhất trong X". Để có thể trả lời cho những câu hỏi như vậy, số lượng điểm dữ liệu mà máy yêu cầu để suy ra một thuật toán sẽ rất lớn. Trong trường họp học có giám sát, máy có thể được huấn luyện thậm chí khoảng vài nghìn điểm dữ liệu. Tuy nhiên trong trường học học không giám sát, số điểm dữ liệu được chấp nhận hợp lý cho việc học tập bắt đầu từ vài triệu điểm dữ liệu. Ngày nay, dữ liệu thường có sẵn rất nhiều. Dữ liệu lý tưởng là dữ liệu đã được xử lý. Tuy nhiên, lượng dữ liệu liên tục được tạo ra trong mạng xã hội, hầu hết trong các trường hợp, việc quản lý dữ liệu là bất khả thiHình ở dưới đây cho thấy ranh giới gữa các chấm màu vàng và đỏ được xác định bởi học không giám sát. Bạn có thể thấy rõ ràng máy sẽ có thể xác định lớp của từng chấm đen với độ chính xác khá tốt.
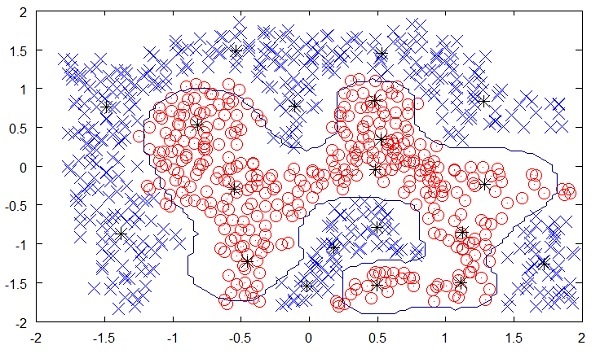
Việc học không giám sát đã cho thấy một thành công lớn trong nhiều ứng dụng AI hiện đại, chẳng hạn như nhận diện khuôn mặt, phát hiện đối tượng, v.v.
3. Reinforcement Learning :
Tôi có một chú chó cưng tên là Lu .Ta sẽ xem xét việc huấn luyện Lu như thế nào. Tôi ném quả bóng đến một khoảng cách nhất định và yêu cầu Lu lấy nó mang trở lại cho tôi. Mỗi khi Lu làm đúng, tôi thưởng cho nó một đồ ăn. Dần dần nó sẽ biết rằng công việc nó đang làm là đúng. Khái niệm này được áp dụng trong học tăng cường. Kỹ thuật này ban đầu được phát triển cho các máy chơi game. Máy được đưa ra một thuật toán để phân tích tất cả các nước đi có thể xảy ra ở mỗi giai đoạn của trò chơi. Máy có thể chọn ngẫy nhiên một trong các bước di chuyển. Nếu nước đi đúng, máy được thưởng, nếu không sẽ bị phát. Từ từ, máy sẽ bắt đầu phân biệt được các bước đi đúng và sai, sau nhiền lần lặp lại sẽ học cách giải câu đố trò chơi với độ chính xác cao hơn. Độ chính xác của việc giành chiến thắng trong trò chơi sẽ cải thiện khi máy chơi ngày càng nhiều trò chơi.Toàn bộ quá trình có thể được mô tả như sau :
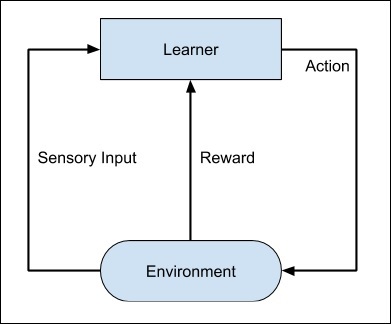
Kỹ thuật học máy này khác so với học có giám sát ở chỗ là bạn không cần cung cấp các cặp input/output được gắn nhãn. trọng tâm là tìm sự cân bằng giữa việc khám phá các giải pháp mới với việc khai thác các giải pháp đã học
4. Deep Learning
Học sâu là một mô hình dựa trên Mạng thần kinh nhân tạo (ANN), cụ thể hơn là Mạng thần kinh hợp pháp (CNN). Có một số kiến trúc được sử dụng trong học sâu như deep neural networks, deep belief networks, recurrent neural networks (RNN),convolutional neural networks(CNN).Các mạng này đã được ứng dụng thành công trong việc giải quyết các vấn đề về thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, tin sinh học, thiết kế thuốc, phân tích hình ảnh y tế và trò chơi. Có một số lĩnh vực khác mà học sâu được chủ động áp dụng. Học sâu đòi hỏi sức mạnh xử lý khổng lồ và dữ liệu khổng lồ, ngày nay thường dễ có sẵn.Ta sẽ nói chi tiết hơn về học sâu trong các chương tới.
5. Deep Reinforcement Learning
Học tăng cường sâu (DRL) kết hợp các kỹ thuật của cả học sâu và tăng cường. Các thuật toán học tăng cường như Q-learning hiện được kết hợp với học sâu để tạo ra một mô hình DRL mạnh mẽ. Kỹ thuật này đã đạt được thành công lớn trong các lĩnh vực robot, trò chơi điện tử, tài chính và chăm sóc sức khỏe. Nhiều vấn đề nan giải trước đây đã được giải quyết bằng cách tạo các mô hình DRL. Có rất nhiều nghiên cứu đang diễn ra trong lĩnh vực này và điều này đang được các ngành theo đuổi rất tích cực.Mình đã giới thiệu ngắn gọn về các mô hình học máy khác nhau, bây giờ chúng ta hãy khám phá sâu hơn một chút về các thuật toán khác nhau có sẵn trong các mô hình này

